JMS based Clustering¶
Introduction¶
The are several approaches to implement a clustered deployment with GeoServer, based on different mixes of data directory sharing plus configuration reload. The JMS based clustering module architecture is depicted in the following diagram:
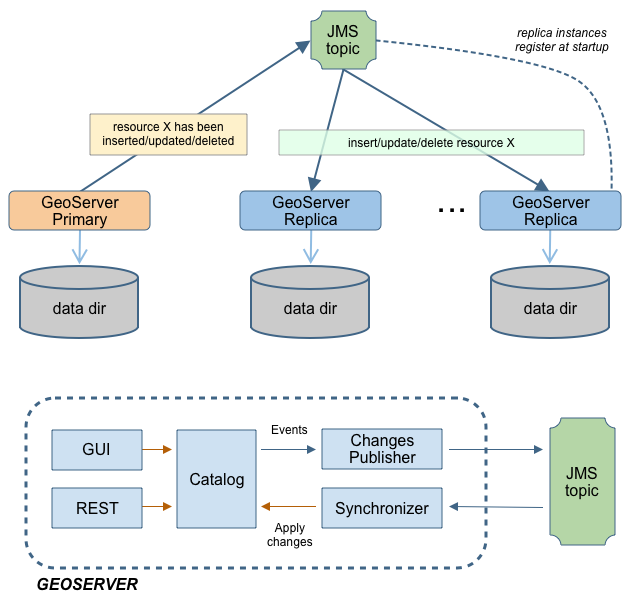
This module implements a robust Primary/Replica approach which leverages on a Message Oriented Middleware (MOM) where:
- The Primaries accept changes to the internal configuration, persist them on their own data directory but also forward them to the Replicas via the MOM
- The Replicas should not be used to change their configuration from either REST or the User Interface, since are configured to inject configuration changes disseminated by the Primary(s) via the MOM
- The MOM is used to make the Primary and the Replicas exchange messages in a durable fashion
- Each Replicas has its own data directory and it is responsible for keeping it aligned with the Primary's one. In case a Replicas goes down when it goes up again he might receive a bunch of JMS messages to align its configuration to the Primary's one.
- A Node can be both Primary and Replica at the same time, this means that we don't have a single point of failure, i.e. the Primary itself
Summarizing, the Primary as well as each Replicas use a private data directory, Replicas receive changes from the Primary, which is the only one where configuration changes are allowed, via JMS messages. Such messages transport GeoServer configuration objects that the Replicas inject directly in their own in-memory configuration and then persist on disk on their data directory, completely removing the need for a configuration reload for each configuration change.
To make things simpler, in the default configuration the MOM is actually embedded and running inside each GeoServer, using multicast to find its peers and thus allowing for a clustering installation without the need to have a separate MOM deploy.
Description¶
The GeoServer Primary/Replica integration is implemented using JMS, Spring and a MOM (Message Oriented Middleware), in particular ActiveMQ. The schema in Illustration represents a complete high level design of Primary/Replica platform. It is composed by 3 distinct actors:
- GeoServer Primary
- GeoServer Replicas
- The MOM (ActiveMQ)
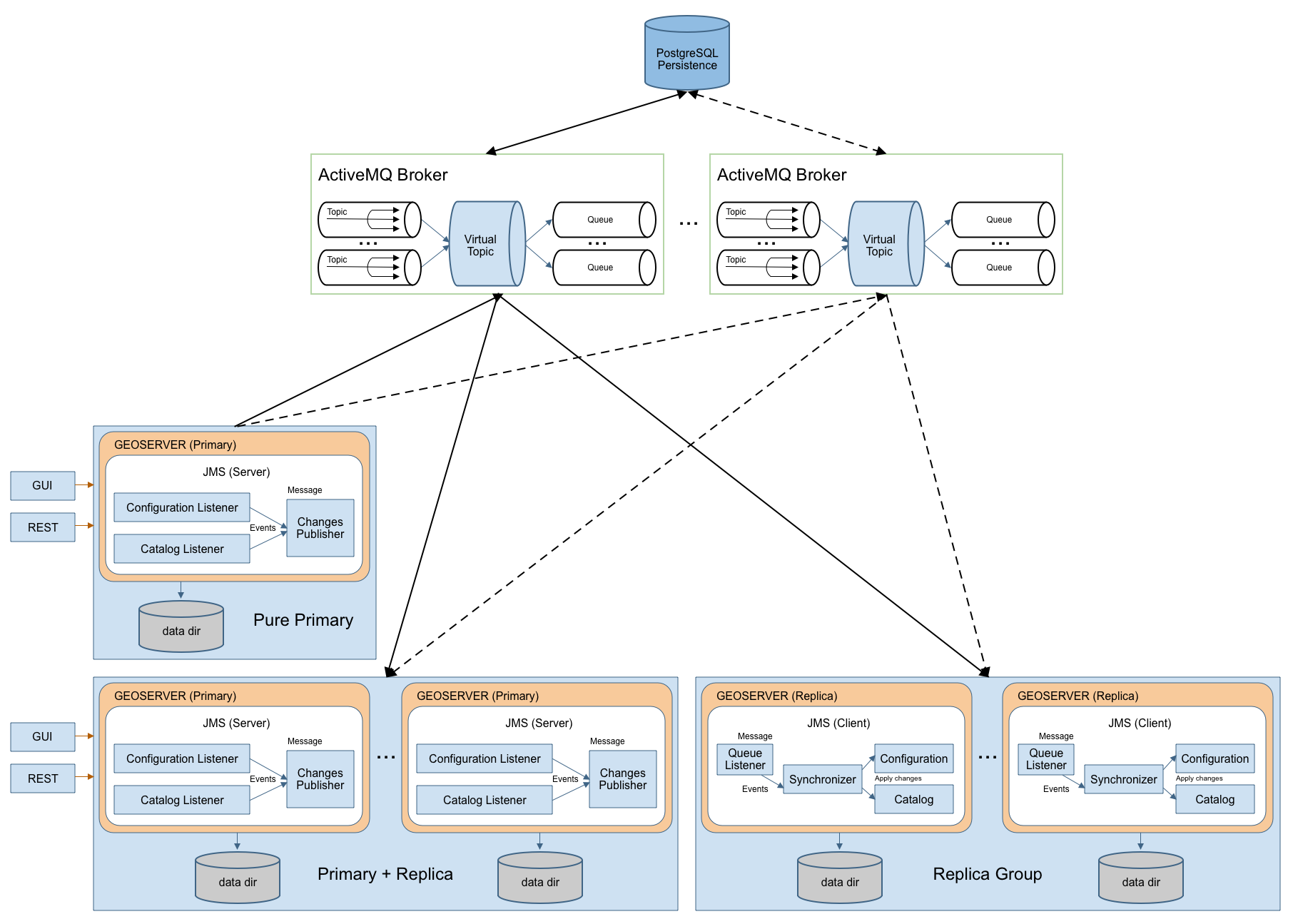
This structure allows to have:
- Queue fail-over components (using MOM).
- Replica down are automatically handled using durable topic (which will store message to re-synch changes happens if one of the replicas is down when the message was made available)
- Primary down will not affect any replicas synchronization process.
This full blown deployment is composed by:
- A pure Primary GeoServer(s), this instance can only send events to the topic. It cannot act as a replica
- A set of GeoServer which can work as both Primary and Replica. These instances can send and receive messages to/from the topic. They can work as Primaries (sending message to other subscribers) as well as Replicas (these instances are also subscribers of the topic).
- A set of pure Replicas GeoServer instances which can only receive messages from the topic.
- A set of MOM brokers so that each GeoServer instance is configured with a set of available brokers (failover). Each broker use the shared database as persistence. Doing so if a broker fails for some reason, messages can still be written and read from the shared database.
All the produced code is based on spring-jms to ensure portability amongst different MOM, but if you look at the schema, we are also leveraging ActiveMQ VirtualTopics to get dynamic routing (you can dynamically attach primary and replica).
The VirtualTopics feature has also other advantages explained here: http://activemq.apache.org/virtual-destinations.html
As said above, in the default configuration the MOM runs inside GeoServer itself, simplifying the topology and the setup effort.
Installation¶
To install the jms cluster modules into an existing GeoServer refer to the Installation page
How to configure GeoServer Instances¶
The configuration for the GeoServer is very simple and can be performed using the provided GUI or modifying the cluster.properties file which is stored into the GEOSERVER_DATA_DIR under the cluster folder (e.g. ${GEOSERVER_DATA_DIR}/cluster).
To override the default destination of this configuration file you have to setup the CLUSTER_CONFIG_DIR variable defining the destination folder of the cluster.properties file. This is mandatory when you want to share the same GEOSERVER_DATA_DIR, but not required if you are giving each GeoServer its own data directory.
In case of shared data directory, it will be necessary to add a different system variable to each JVM running a GeoServer, e.g.:
-DCLUSTER_CONFIG_DIR=/var/geoserver/clusterConfig/1to the JVM running the first node-DCLUSTER_CONFIG_DIR=/var/geoserver/clusterConfig/2to the JVM running the second node- and so on
If the directories are missing, GeoServer will create them and provide a initial cluster.properties with reasonable defaults.
Instance name¶
The instance.name is used to distinguish from which GeoServer instance the message is coming from, so each GeoServer instance should use a different, unique (for a single cluster) name.
Broker URL¶
The broker.url field is used to instruct the internal JMS machinery where to publish messages to (primary GeoServer installation) or where to consume messages from (replica GeoServer installation). Many options are available for configuring the connection between the GeoServer instance and the JMS broker, for a complete list, please, check http://activemq.apache.org/configuring-transports.html. In case when (recommended) failover set up is put in place multiple broker URLs can be used. See http://activemq.apache.org/failover-transport-reference.html for more information about how to configure that. Note GeoServer will not complete the start-up phase until the target broker is correctly activated and reachable.
Limitations and future extensions¶
Data¶
NO DATA IS SENT THROUGH THE JMS CHANNEL The clustering solution we have put in place is specific for managing the GeoServer internal configuration, no data is transferred between primary and replicas. For that purpose use external mechanisms (ref. [GeoServer REST]). In principle this is not a limitation per se since usually in a clustered environment data is stored in shared locations outside the data directory. With our solution this is a requirement since each replicas will have its own private data directory.
Things to avoid¶
- NEVER RELOAD THE GEOSERVER CATALOG ON A PRIMARY: Each primary instance should never call the catalog reload since this propagates the creation of all the resources, styles, etc to all the connected replicas.
- NEVER CHANGE CONFIGURATION USING A PURE REPLICA: This will make the configuration of the specific replica out of synch with the others.
Refs:¶
Bibliography:¶
[JMS specs] Sun microsystems - Java Message Service - Version 1.1 April 12, 2002
[JMS] Snyder Bosanac Davies - ActiveMQ in action - Manning
[GeoServer] http://docs.geoserver.org/
[GeoServer REST] http://docs.geoserver.org/latest/en/user/rest/index.html#rest
[ActiveMQ] http://activemq.apache.org/