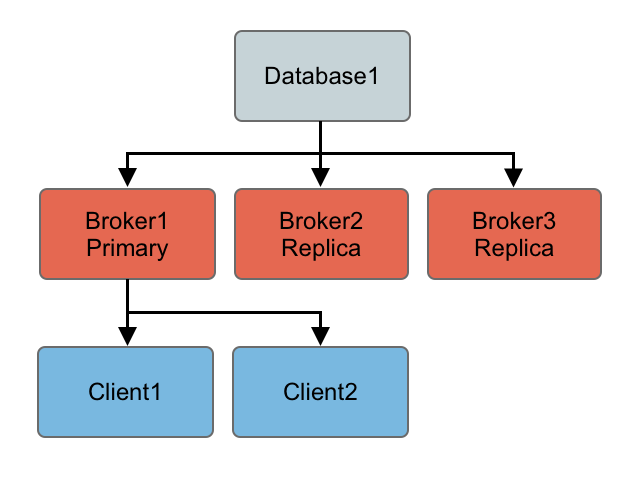
At any time you can restart other brokers which join the cluster and start as replicas waiting to become a primary if the primary is shutdown or a failure occurs.
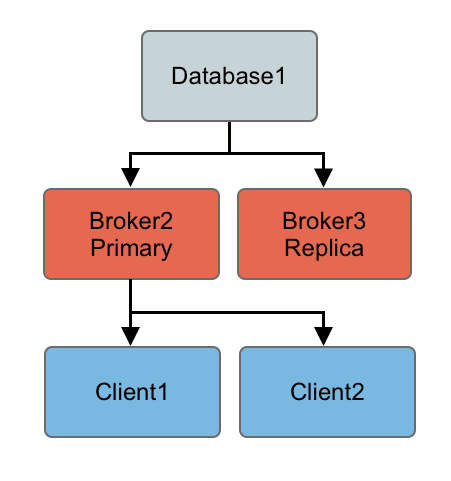
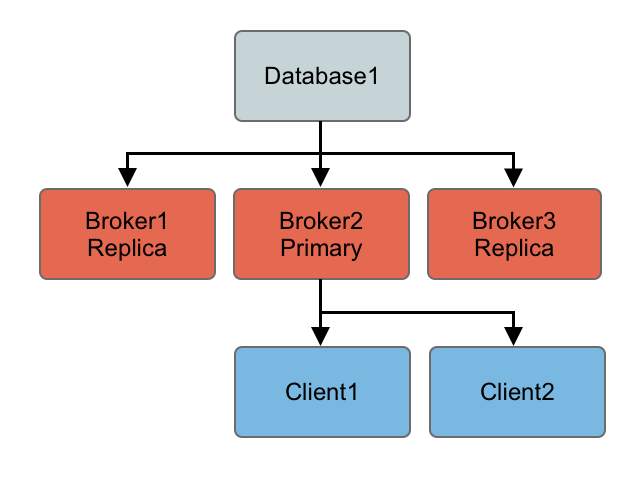
So the following topology is created after a restart of an old primary…
Note
If you have a SAN or shared file system it can be used to provide high availability such that if a broker is killed, another broker can take over immediately.
Ensure your shared file locks work
Note that the requirements of this failover system are a distributed file system like a SAN for which exclusive file locks work reliably. If you do not have such a thing available then consider using Primary/Replica instead which implements something similar but working on commodity hardware using local file systems which ActiveMQ does the replication.
Was testing using OCFS2 and both brokers thought they had the primary lock - this is because “OCFS2 only supports locking with ‘fcntl’ and not ‘lockf and flock’, therefore mutex file locking from Java isn’t supported.”
From http://sources.redhat.com/cluster/faq.html#gfs_vs_ocfs2 :
OCFS2: No cluster-aware flock or POSIX locks
GFS: fully supports Cluster-wide flocks and POSIX locks and is supported.
In the event of an abnormal NFSv3 client termination (i.e., the ActiveMQ primary broker), the NFSv3 server will not timeout the lock that is held by that client. This effectively renders the ActiveMQ data directory inaccessible because the ActiveMQ replica broker can’t acquire the lock and therefore cannot start up. The only solution to this predicament with NFSv3 is to reboot all ActiveMQ instances to reset everything.
Use of NFSv4 is another solution because it’s design includes timeouts for locks. When using NFSv4 and the client holding the lock experiences an abnormal termination, by design, the lock is released after 30 seconds, allowing another client to grab the lock. For more information about this, see this blog entry.